Borg 系统是Google广泛使用的一个集群管理器,有着"kubernetes的前身"之称,本文介绍了Borg的架构和许多特性。
Borg的主要优点:
- 隐藏资源管理和故障处理的详细信息,以便其用户可以专注于应用程序开发;
- 具有很高的可靠性和可用性,并支持相同的应用;
- 让我们有效地在成千上万的计算机上运行工作负载。
From User’s Perspective
工作负载
工作负载主要分为两类:
- 长期运行的服务
- 对性能波动非常敏感,直接面向end-user
- 批处理作业
- 耗时较长,对性能波动敏感低
优先级高的Borg job被称为prob,反之为non-prob, 大多数prob为长期运行服务,non-prob多为批处理作业。
用户通过向Borg发出远程过程调用(RPC)(通常是从命令行工具,其他Borg作业或我们的监视系统)来对作业进行操作。
优先级,配额与准入控制
Borg通过为作业分配优先级解决工作量超过容量的问题。 高优先级任务可以以低优先级任务为代价获得资源,即使这涉及抢占(杀死)后者。
配额用于决定允许哪些作业进行调度。 配额表示为一段时间(通常为几个月)内给定优先级的资源数量(CPU,RAM,磁盘等)的向量。 数量指定了用户的作业请求一次可以请求的最大资源量(例如,“从现在到7月底,单元xx中的产品优先级为20 TiB RAM”)。 配额检查是准入控制的一部分,而不是计划的一部分:配额不足的作业在提交后将立即被拒绝。这也说明,配额实在Borg之外进行的,取决于物理条件等。
命名与监控
为了找到创建和放置的任务,Borg为每个任务创建了一个稳定的“ Borg名称服务”(BNS)名称,其中包括单元名称,作业名称和任务编号。
几乎在Borg下运行的每个任务都包含一个内置的HTTP服务器,该服务器发布有关任务运行状况和成千上万个性能指标(例如RPC延迟)的信息。 Borg监视运行状况检查URL,并重新启动无法及时响应或返回HTTP错误代码的任务。监视工具可跟踪其他数据,以用于仪表板并针对违反服务水平目标(SLO)的情况发出警报。
Borg架构
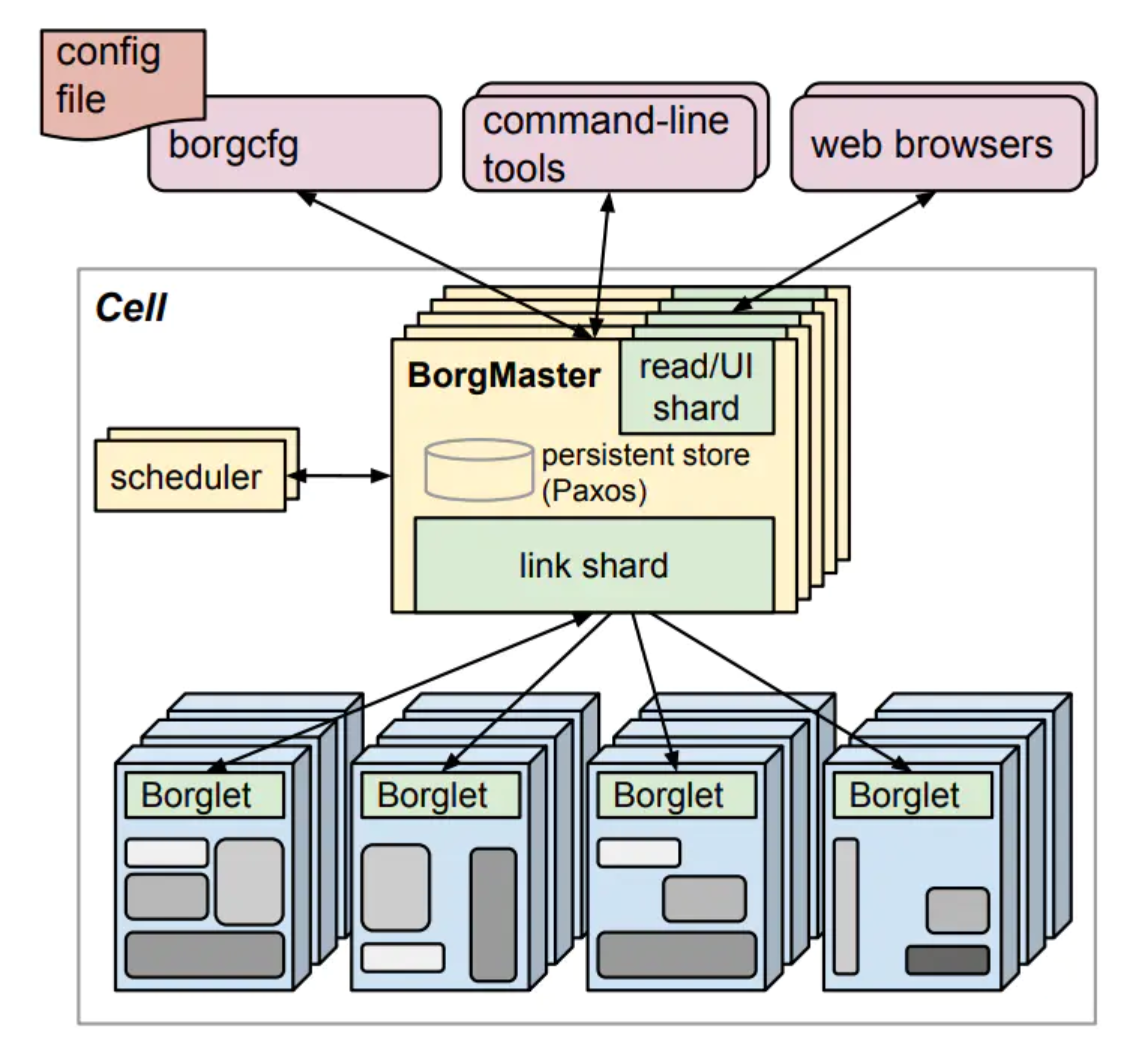
一个Borg单元由一组计算机,一个逻辑上集中的控制器(称为Borgmaster)和一个称为Borglet的代理进程组成,该进程在该单元中的每台计算机上运行。
Borg master
每个单元的Borgmaster包含两个进程:Borgmaster主进程和一个单独的调度程序(Scheduling)。 Borgmaster主进程处理客户端RPC,这些RPC会改变状态(例如,创建作业)或提供对数据的只读访问权限(例如,查找作业)。它还为系统中的所有对象(机器,任务,分配等)管理状态机,与Borglets通信,并提供Web UI作为Sigma(类似Dashboard的Web UI)的备份。
Scheduling
提交作业后,Borgmaster将其持久地记录在Paxos Store中,并将该作业的任务添加到等待队列中。 调度程序会对此进行异步扫描,如果有足够的可用资源满足任务的约束,调度程序会将任务分配给计算机。 (调度程序主要在任务(Task)而不是作业(Job)上运行)。
Scheduling 进程对worker机器进行“打分”并为他们分配适合的任务,打分本身是一个开销很大的过程。
Scalability
Borg在提高Scalability方面做的事:
- 分数缓存:评估可行性并为机器评分是昂贵的,因此Borg会缓存分数,直到机器的属性或任务发生变化。
- 等价类:Borg不会对每台机器上的每个待处理任务进行挖掘可行性,并为所有可行的机器评分,Borg只对每个等价项进行可行性和评分类–一组具有相同要求的任务。
- 宽松的随机化:计算大型单元中所有计算机的可行性和分数是浪费的,因此调度程序以随机顺序检查计算机,直到找到“足够”可行的计算机进行评分,然后在其中选择最佳计算机放。
Availability
可用性方面:
- 如有必要,可在新的机器上自动重新安排已撤消的任务;
- 通过在不同的故障域(例如机器,机架和电源域)中分散作业的任务,减少相关的故障;
- 限制允许的任务中断率和作业中可以在维护活动(例如OS或机器升级)中同时关闭的任务数量;
- 使用声明性的期望状态表示和等效的等效更改操作,以便失败的客户端可以无害地重新提交任何被遗忘的请求;
- 对无法访问的计算机寻找新位置的速率限制,因为它无法区分大规模计算机故障和网络分区;
- 避免重复任务:导致任务或机器崩溃的机器配对;
- 通过反复重新运行logsaver任务来恢复写入本地磁盘的关键中间数据,即使已将附加到它的分配终止或移动到另一台计算机也是如此。用户可以设置系统尝试运行多长时间;通常几天。
Utilization
资源利用率方面:
- Cell sharing(单元共享)
- 机器都同时执行生产任务和非生产任务
- Large cells
- 建立大型单元,既可以运行大型计算,又可以减少资源碎片。
- Fine-grained resource requests(细粒度的资源请求)
- Borg用户以毫核心为单位请求CPU,以字节为单位请求内存和磁盘空间。
- Resource reclamation(资源回收)
- Isolation
- 安全隔离:使用Linux chroot jail作为同一台计算机上多个任务之间的主要安全隔离机制;在作为Borg任务运行的KVM进程中运行每个托管的VM
- 性能隔离:所有Borg任务都在基于Linux cgroup的资源容器中运行,并且Borglet操纵容器设置;LS任务保留整个物理CPU内核
经验教训
The Bad
- 作业是唯一限制任务的分组机制
- Borg没有一流的方法来将整个多职位服务作为单个实体进行管理,也无法引用服务的相关实例(例如,金丝雀canary和生产轨道production tracks)
- 每台机器上的任务使用同一个IP地址会使事情变得复杂。
- Borg必须安排端口作为资源;任务必须预先声明它们需要多少个端口,并愿意在启动时被告知要使用哪些端口;Borglet必须强制执行端口隔离;并且命名和RPC系统必须处理端口以及IP地址。
- 针对高级用户提供了大量可微调程序的API
- 使“休闲”用户的工作变得更加困难
The Good
- 分配是有用的
- 集群管理不仅仅是任务管理
- 其他好处:命名和负载平衡
- 主机是分布式系统的内核
关于 K8S
- 为了避免此类困难(指作业是唯一限制任务的分组机制),Kubernetes拒绝job notion,而是使用label(arbitrary key/value pairs)来组织其调度单位(pod)。可以通过将job:jobname标签附加到一组pod来实现等效的Borg job,但是也可以表示任何其他有用的分组,例如service,tier或release-ty[e(例如,production,staging,test)。 Kubernetes中的操作通过标签查询来标识其目标,标签查询选择操作应应用于的对象。这种方法比作业的单个固定分组具有更大的灵活性。
- 由于Linux名称空间,VM,IPv6和软件定义的网络的出现,Kubernetes可以采用一种更加用户友好的方法来消除这些复杂性:每个pod和服务都有其自己的IP地址,从而允许开发人员选择端口而不是要求其软件适应基础架构选择的,并消除管理端口的基础架构复杂性。
- Kubernetes相当于alloc的是pod,pod是一个或多个容器的资源包络,这些容器总是被调度到同一台机器上并且可以共享资源。 Kubernetes在同一个pod中使用辅助容器而不是在alloc中使用任务,但是想法是相同的。
- Kubernetes使用服务抽象支持命名和负载平衡:服务具有名称和由标签选择器定义的动态Pod集。群集中的任何容器都可以使用服务名称连接到服务。在幕后,Kubernetes会自动在与标签选择器匹配的Pod之间对与服务的连接进行负载平衡,并跟踪Pod在哪里运行,因为它们由于故障而随着时间重新安排。
- Kubernetes旨在复制Borg的许多自省技术。例如,它附带了诸如cAdvisor之类的工具,用于资源监视以及基于Elasticsearch / Kibana和Fluentd的日志聚合。可以查询主对象以获取其对象状态的快照。 Kubernetes具有统一的机制,所有组件都可以使用该机制来记录可供客户端使用的事件(例如,计划中的Pod,容器发生故障)。
- 在“主机是分布式系统的内核”上,Kubernetes架构更进一步:它的核心是一个API服务器,该API服务器仅负责处理请求和处理底层状态对象。集群管理逻辑构建为小型、可组合的微服务,这些微服务是此API服务器的客户端,例如复制控制器(replication controller),该控制器在出现故障时可维护所需数量的Pod副本,以及节点控制器(node controller),它管理机器的生命周期。
If you like this blog or find it useful for you, you are welcome to comment on it. You are also welcome to share this blog, so that more people can participate in it. If the images used in the blog infringe your copyright, please contact the author to delete them. Thank you !