众所周知Docker的实现基于Linux内核提供的cgroup和namespace两个功能,本篇文章的目的是在chcore这一微内核架构上实现这两个功能,也就是实现微内核上的容器功能。
实现Cgroup
需要考虑两个方面
- 内核层面的cgroup支持
- 与内核交互的接口
Linux内核实现了一系列的数据结构如cgroup_subsys和cftype等,具体数据结构关系如下如所示,有够复杂
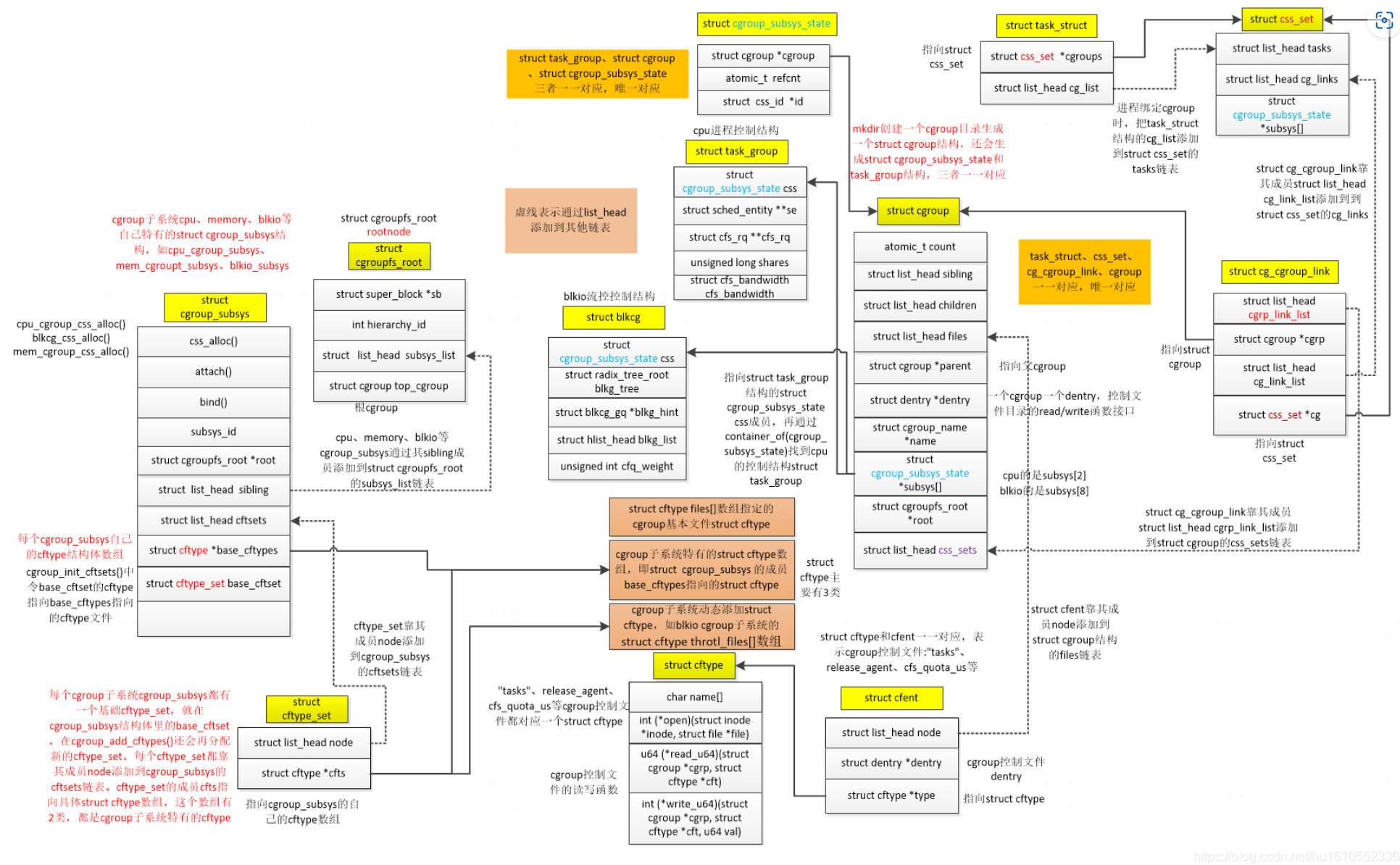
关于cgroup的原理和源码解析,可以参考: CGroup 实现原理 , CGroup源码分析
Linux中的Cgroup实现简析
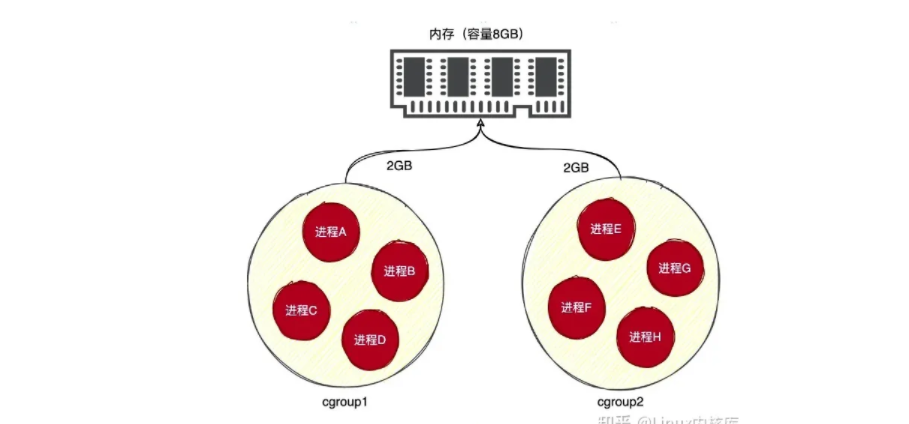
Linux将进程以Cgroup为单位切分实现资源隔离,效果如图所示
实际上cgroup的实现相当复杂,因为涉及到多种资源的控制,下面我主要从设计者的角度分析其实现思路,并简要结合源码分析。
实现一个简单的进程组
其实简单来说,只要我们定义一个数据结构,能够记录一组进程以及它们对应的资源限制即可。
以下是一个朴素的设计思路:
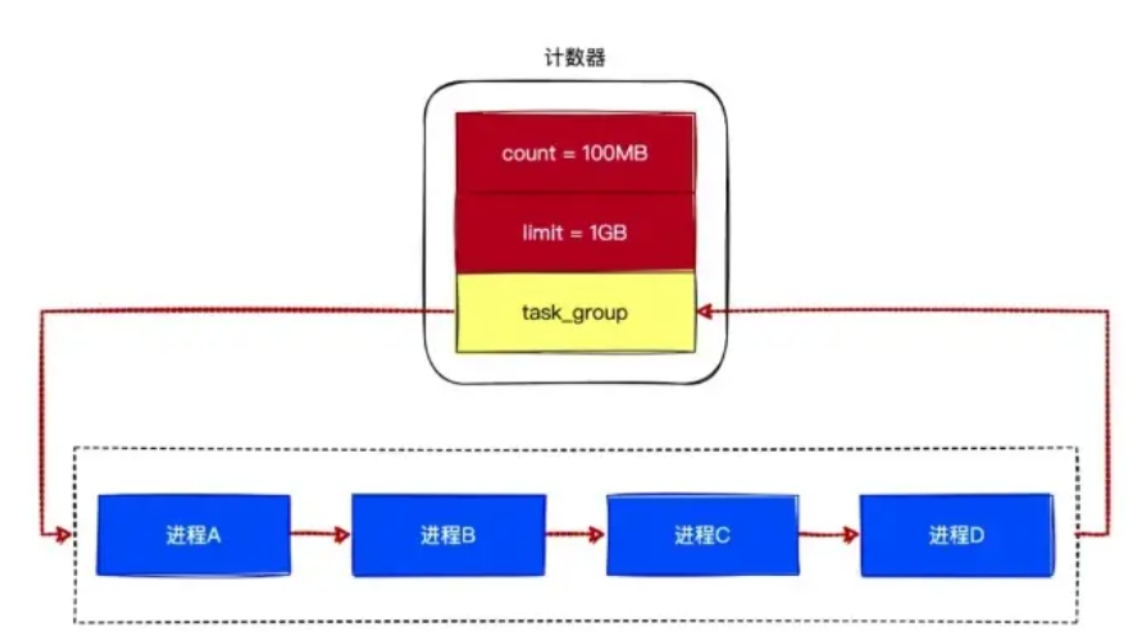
我们通过链表来将进程组织成进程组,并且在计数器中增加一个 task_group 字段,让其指向进程组。当进程组中的进程申请内存时,可以通过指针来找到对应的计数器,并且增加计数器的 count 字段。
就这样,我们设计了一个简单的进程组功能。如果系统只有内存这种资源的话,的确可以这样设计。但是系统除了内存,还有CPU、硬盘和网络这些资源,所以 Linux 创建了一种比较通用的方式来组织进程组,也就是cgroup。
通过Hierarchy组织CGroup
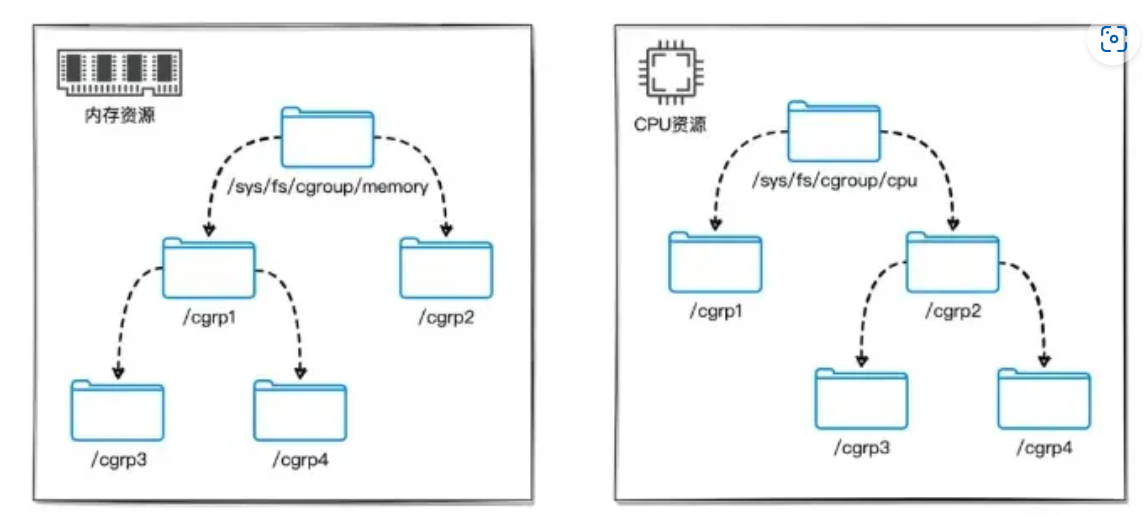
Linux将CGroup 当成是一个目录,由于目录有层级关系,所以 CGroup 也有层级关系,如下图所示:
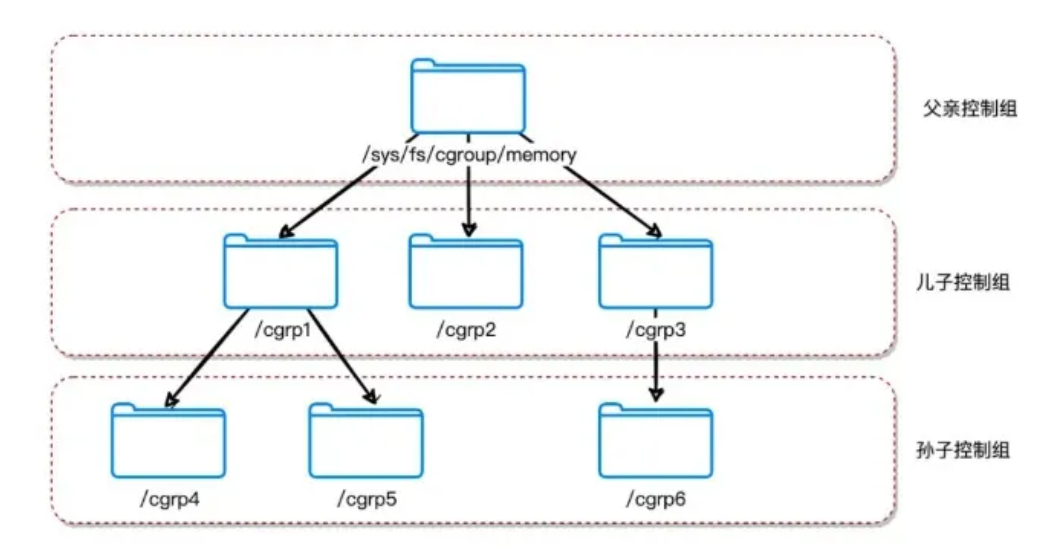
每个控制组都记录着自己包含的进程列表(实际上,它被记录在对应目录中一个叫tasks的文件中)。
在内核中,控制组使用 cgroup 结构来表示,其定义如下:
1 | struct cgroup { |
内核通过 cgroup 结构的 sibling、children 和 parent 这3个字段来将 控制组 组织成一棵树状结构,这就是组织cgroup的hierarchy。如下图所示:
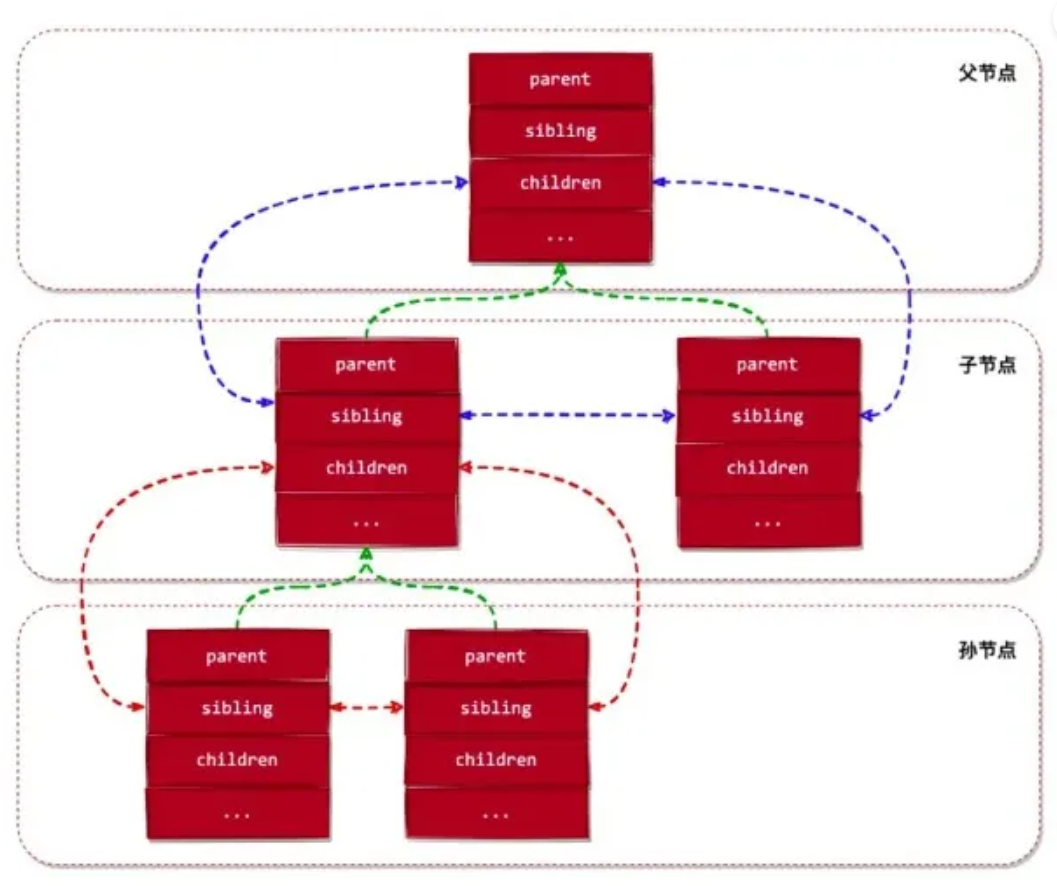
关联Hierarchy与Subsys
cgroup 结构的 subsys 字段表示当前控制组关联的子系统状态对象,也就是cpu或者memory这种资源对象,一个cgroup可以关联到多个subsys,处在同一个Hierarchy的cgroup必然关联到同一个subsys。
在Linux中,每种subsys都由一个名为 cgroup_subsys 的结构来描述,其定义如下:
1 | struct cgroup_subsys { |
在内核中,hierarchy的根结点使用 cgroupfs_root结构来表示, 定义如下:
1 | struct cgroupfs_root { |
所以将hierarchy与subsys建立关联就是将cgroup_subsys的cgroupfs_root修改为对应的根节点即可。
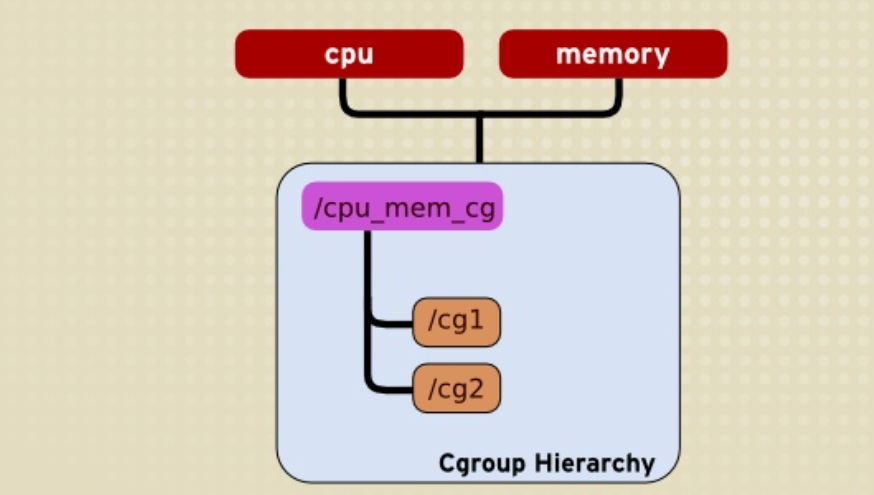
在 Linux 内核中,可以存在多个 hierarchy,每个hierarchy可以关联一个或多个 资源控制子系统,但同一个 subsys 不能关联到多个hierarchy中(这其实也很好理解,因为cgroup_subsys的cgroupfs_root只有一个)。如下图所示:
在上述两图中,memory和cpu这两个subsys都已经被关联,因此不可能再有新的hierarchy与他们产生关联,但是支持将他们关联到同一个hierarchy上,如
在 Linux 内核中,有个名为 rootnode 的根层级,在系统启动后,由内核自动创建并且初始化的层级。系统启动后,所有的资源控制子系统都关联到此层级。
如果用户想把资源控制子系统关联到其他层级,那么可以使用 mount 命令来进行挂载,如下命令所示:
1 | $ mount -t cgroup -o memory memory /sys/fs/cgroup/memory |
上面的命令用于将内存subsys重新关联到 /sys/fs/cgroup/memory 这个hierarchy。
资源统计对象
将hierarchy与subsys关联之后,我们还需要记录每个cgroup在这个subsys上使用的资源总量。
在上面的实例中,我们使用一个计数器来统计进程组对内存资源的使用情况,每个 cgroup 都需要一个这样的计数器来统计和限制进程组对内存资源的使用。
在 Linux 内核中也有类似的 “计数器“,使用 cgroup_subsys_state 结构来表示(我们称它为 资源统计对象),其定义如下:
1 | struct cgroup_subsys_state { |
cgroup_subsys_state 结构看起来非常简单,这只是表面现象。内核为了将所有的 cgroup_subsys_state 抽象化(也就是都能用 cgroup_subsys_state 指针来指向所有类型的 资源统计对象),才定义出这个通用的部分,实际上的 cgroup_subsys_state 是比较复杂的。
例如内存的基于cgroup_subsys_state的资源统计对象定义如下:
1 | struct mem_cgroup { |
mem_cgroup 结构与 cgroup_subsys_state 结构的关系如下图所示:
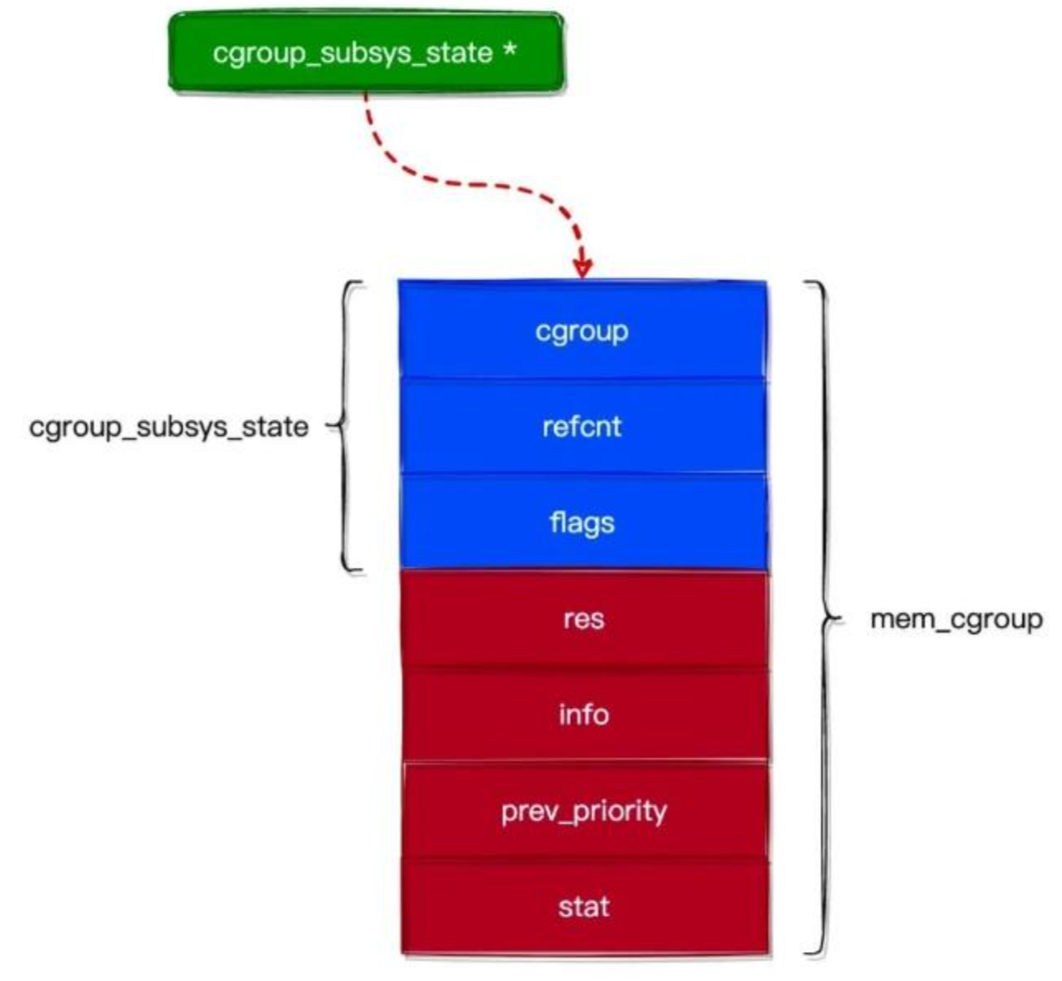
资源统计对象 必须与 控制组 绑定,才能实现限制 控制组 对资源的使用。前面我们了解到 cgroup 结构中有个名为 subsys 的字段,如下代码所示:
1 | struct cgroup { |
可以看出,subsys 字段是一个 cgroup_subsys_state 结构的数组,数组的大小为系统支持的 资源控制子系统 数(也就是说,数组上的每个槽位对应着一个子系统资统计对象)。如下图所示:
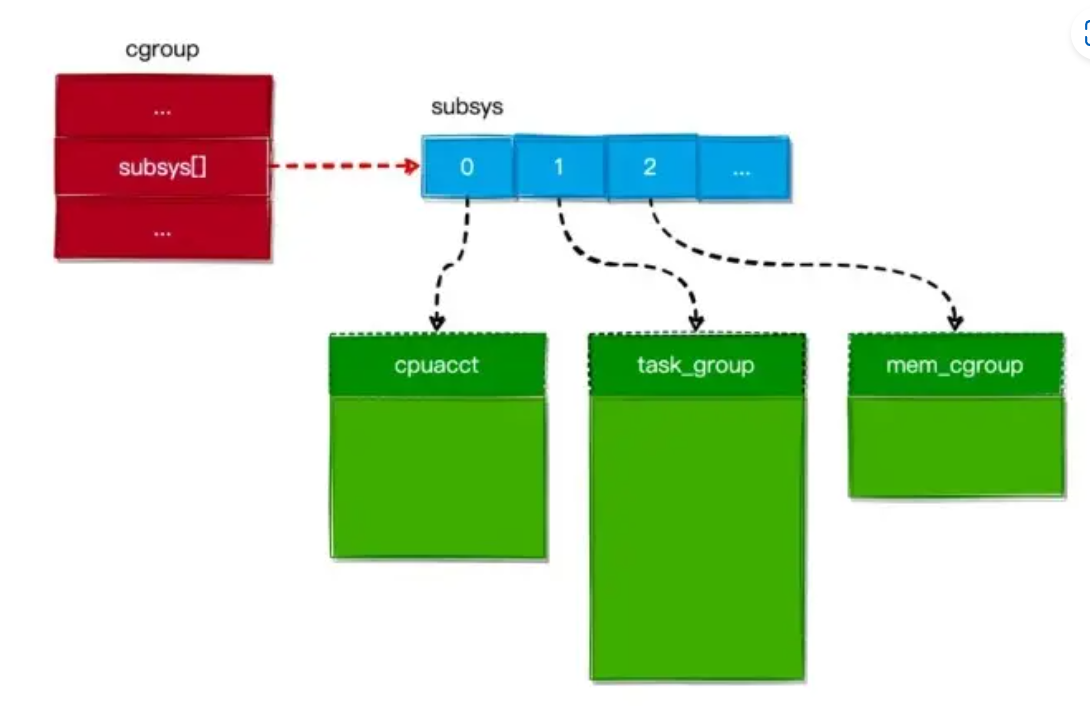
在 Linux 内核中,一个进程可以属于多个 控制组,而每个 控制组 又关联着一个或多个 资源统计对象。所以,一个进程所关联的 资源统计对象 是其所在 控制组 关联的 资源统计对象 的集合。这句话有点难懂,我们用一幅图来说明:
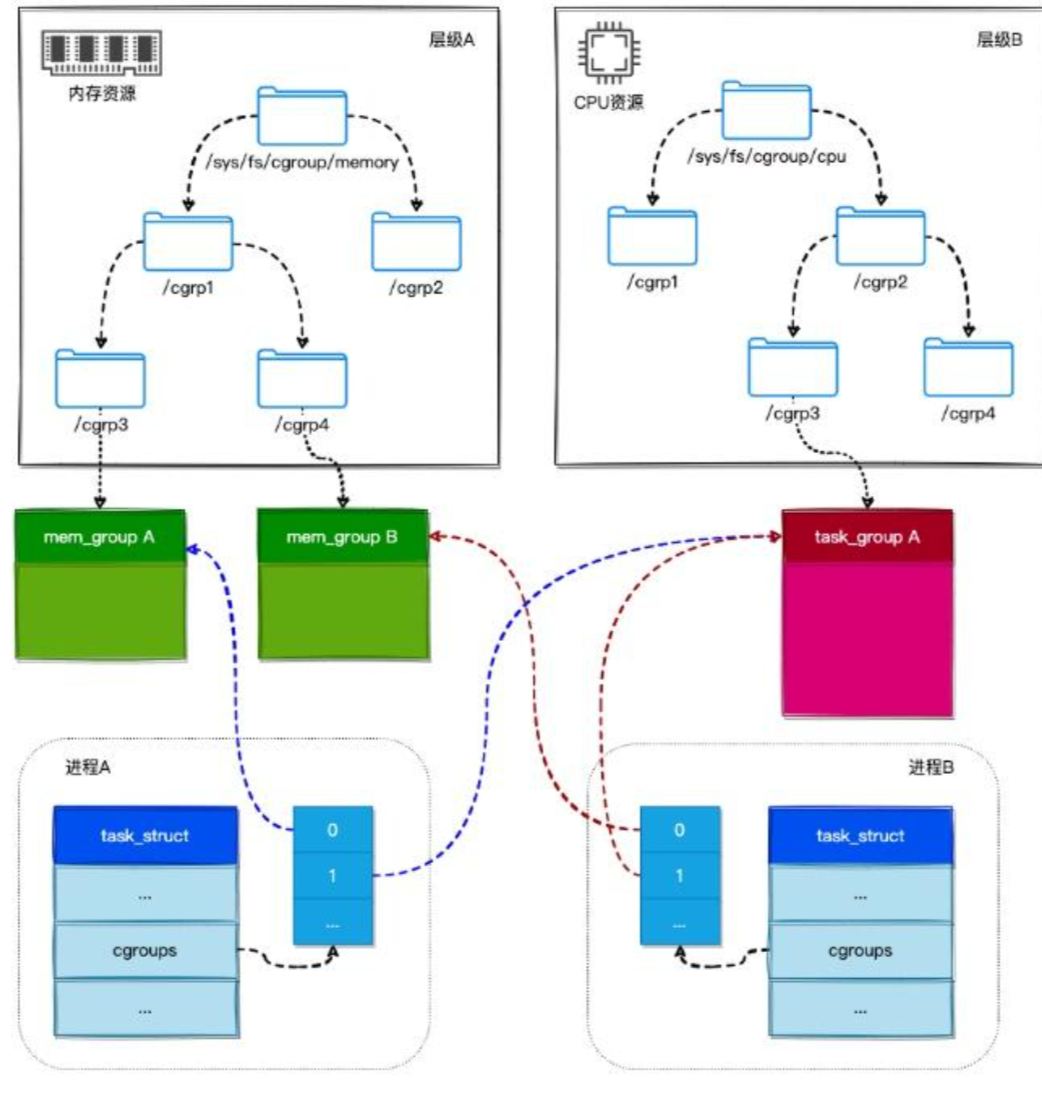
如上图所示:
进程A属于控制组/sys/fs/cgroup/memory/cgrp1/cgrp3和控制组/sys/fs/cgroup/cpu/cgrp2/cgrp3,所以进程A就关联了mem_group A和task_group A这两个资源统计对象。进程B属于控制组/sys/fs/cgroup/memory/cgrp1/cgrp4和控制组/sys/fs/cgroup/cpu/cgrp2/cgrp3,所以进程B就关联了mem_group B和task_group A这两个资源统计对象。
进程通过 css_set 结构来收集不同cgroup的 资源统计对象,其定义如下:
1 | struct css_set { |
在 进程描述符结构(task_struct) 中有个指向 css_set 结构的指针,如下所示:
1 | struct task_struct { |
所以,当把一个进程添加到一个 cgroup 时,将会把 cgroup 关联的 资源统计对象 添加到进程的 cgroups 字段中,从而使进程受到这些 资源统计对象 的限制 (这句话是实现cgroup控制的进程的精髓)。
如何在Chcore中实现Cgroup功能
我们先考虑实现memory的cgroup隔离,TA为我们提供了一个可能的思路:
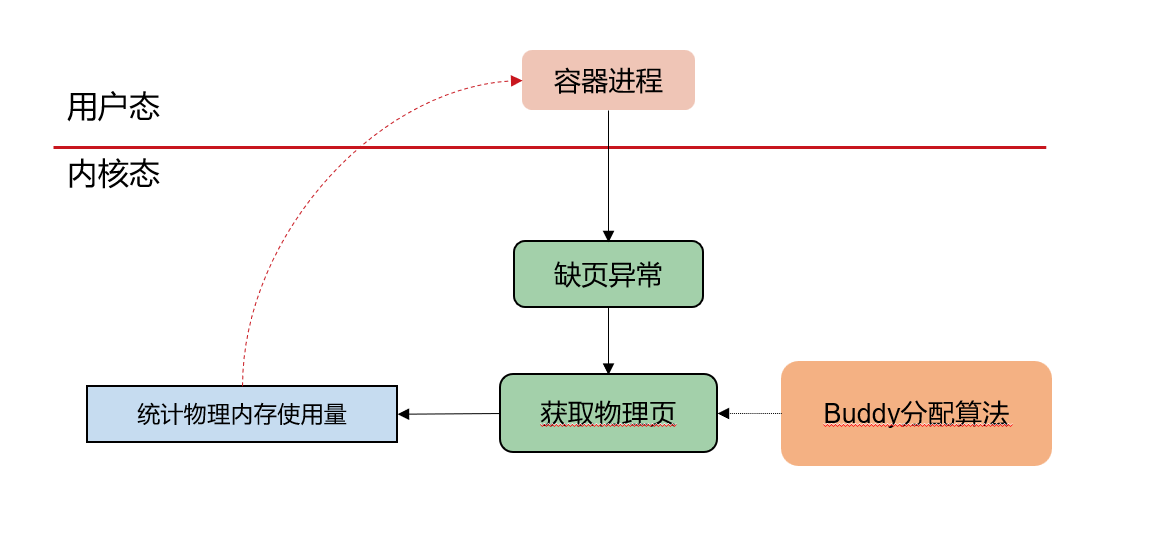
基本思路如下:
- 在容器进程尝试分配内存并触发page fault尝试通过buddy算法获取物理页的时候修改该进程的物理内存使用量
- 该进程属于某个进程集合,且存在文件记录了这些进程的内存使用总量和上限
- 当内存总量超过上限时会触发异常(例如OOM或拒绝分配且抛出警告)
- 考虑一些corner case: Spawn/IPC 不破坏性能隔离/资源隔离
这个思路是显而易见的,因此我们需要弄清楚的问题就是:
- chcore的内存申请的整个链路
- 怎么保存进程组的内存使用信息
复习一下chcore的内存分配吧!

这里我们需要考虑的是fd不为1的情况,也就是内存分配而非文件内存映射,调用chcore_sys_call后,chcore会切换到el1特权级,并根据sys_call的table选择需要调用的handle函数,,以下为sys_handle_mmap的源代码:
1 | u64 sys_handle_mmap(u64 addr, size_t length, int prot, int flags, int fd, |
- 创建 pmobject 对象(
obj_alloc$\rightarrow$kzalloc$$\rightarrow$$kmalloc) - 创建 pmobject 对象的内核对象句柄
cap(cap_alloc$$\rightarrow$$kmalloc) - 映射 pmobject 对象到虚拟地址空间:
- 获取当前进程的 vmspace 对象。
- 通过 get_vmr_prot 将传入的保护标志转换为对应的虚拟内存区域属性。
- 调用 vmspace_mmap_with_pmo ,将新创建的 pmobject 对象映射到进程的虚拟地址空间中。
- 释放 pmobject 对象的句柄和引用计数,避免内存泄漏,使用 obj_put 函数释放 pmobject 内核对象句柄。
- 返回映射区域的起始地址给 map_addr 变量。
再回顾一下chcore的kernel异常处理流程:
在kernel/arch/xxx/irq/irq_entry.上S定义分发异常。
- 若为
IRQ,则在irq_entry.c中的handle_irq交给平台相关的plat_handle_irq处理。最后调用scheduler切换到合适的线程。 - 若为
SYSCALL,则利用kernel/syscall/syscall.c中的syscall_table通过偏移量找到对应函数的入口。 - 若为其他异常,如Page Fault,则在
irq_entry.c中的handle_entry_c根据EC的不同分发到不同的入口。handle_entry_c中传入的两个参数:esr为Exception Syndrome Register,包含了导致这个exception的原因,从manual抄下来的原因在register.h中;address是导致这个异常的地址。
结合以上知识,我们可以产生一些general的想法:
tips
-
先在进程申请/释放内存的时候打印日志
-
构思用怎样的方式存储group->mem_use
-
看看linux是怎么进行文件操作的
-
子进程应该继承父进程的cgroup
-
目前似乎不能pid->cap_group,可能需要加一个全局的数据结构来保存
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !